4-byte Big-Endian file reading
I am trying to understand Disch's tutorial on binary files (http://www.cplusplus.com/articles/DzywvCM9/ ).
Trying to learn based off the above link and this picture: http://img1.wikia.nocookie.net/__cb20130603095305/falloutmods/images/4/49/FRM_Endianess.jpg
Can someone confirm that this is the correct way to read a 4-byte piece of a file encoded in Big-Endian formatting?
Also, this is the correct way for Big-Endian 16-bit?
(Compare with Disch's code in the tutorial)
main would look something like
Edit: Confirmed that my 16-bit code is working using
Still trying stuff for 32-bit. It's hard to tell if I have it backwards or not... the problem might be how it handles 0x00 bytes?
Trying to learn based off the above link and this picture: http://img1.wikia.nocookie.net/__cb20130603095305/falloutmods/images/4/49/FRM_Endianess.jpg
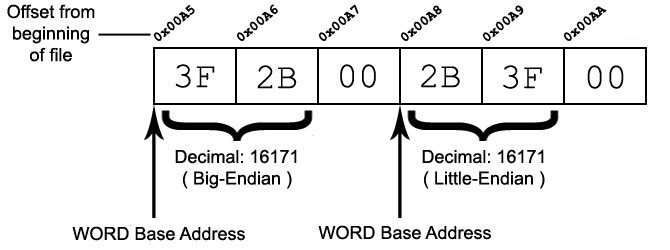{kind=link}
Can someone confirm that this is the correct way to read a 4-byte piece of a file encoded in Big-Endian formatting?
|
|
Also, this is the correct way for Big-Endian 16-bit?
|
|
(Compare with Disch's code in the tutorial)
main would look something like
|
|
Edit: Confirmed that my 16-bit code is working using
|
|
Still trying stuff for 32-bit. It's hard to tell if I have it backwards or not... the problem might be how it handles 0x00 bytes?
Last edited on
| bytes[3] | (bytes[2] << 24) | (bytes[1] << 16) | (bytes[0] << 8); |
| val = bytes[1] | (bytes[0] << 8); |
Thanks for the reply, I will try to apply that, I thought that it needed to be backwards because disch's tutorial was showing little-endian. So I should rather use "unsigned char" instead of just "char"? Huh, I didn't even know that was a thing until I just looked it up. Edit: Or I could just use uint8_t, as I'm not targeting those 12-bit machines. thanks again.
Was my first post's 4-byte code implementing little-endian by mistake, or just non-sense?
Was my first post's 4-byte code implementing little-endian by mistake, or just non-sense?
Last edited on
You have an array of 4 bytes: [0], [1], [2], and [3]
In big endian, the first byte ([0]) is the most significant, and the last byte ([3]) is the least significant.
This means that:
[3] = moves to bit positions 0-7
[2] = moves to bit positions 8-15
[1] = moves to bit positions 16-23
[0] = moves to bit positions 24-31
This is close, but not quite right. You are skipping over positions 24-31 and moving [0] to positions 32-39 (which don't exist in a 32-bit var, hence the warning).
Also, to reiterate what helios already said... don't use char. It's a signed type and therefore you might get weirdness when shifting into a larger variable type.
In big endian, the first byte ([0]) is the most significant, and the last byte ([3]) is the least significant.
This means that:
[3] = moves to bit positions 0-7
[2] = moves to bit positions 8-15
[1] = moves to bit positions 16-23
[0] = moves to bit positions 24-31
val = bytes[3] | (bytes[2] << 8) | (bytes[1] << 16) | (bytes[0] << 32);This is close, but not quite right. You are skipping over positions 24-31 and moving [0] to positions 32-39 (which don't exist in a 32-bit var, hence the warning).
Also, to reiterate what helios already said... don't use char. It's a signed type and therefore you might get weirdness when shifting into a larger variable type.
Yep I deleted what I had, I saw the mistake right away :p Guess I didn't delete quick enough. Also I already had it like
now, I just didn't update the post, my bad. I should be good now, thank you both.
|
|
Last edited on
Topic archived. No new replies allowed.