- Forum
- General C++ Programming
- Incorrect/Partial Output - Stuck please
Incorrect/Partial Output - Stuck please Help!
Hello!
Please help. I'm stuck. Thank you so much :)
I was tasked to create a program that would output the shortest paths to all other nodes. So for example in this photo, with source A, ( https://www.includehelp.com/cpp-tutorial/Images/d0.jpg ) the output will be:
A-B
A-C
A-B-G-E-D
...
Current Output:
*It shows the correct path but I just can't figure out how to somehow connect them.
So far, I have been able to compute the shortest path costs from the source to each node using Dijkstra's Algorithm. However, I can't seem to figure out how to output the "correct path directions" as seen above.
Input:
Please help. I'm stuck. Thank you so much :)
I was tasked to create a program that would output the shortest paths to all other nodes. So for example in this photo, with source A, ( https://www.includehelp.com/cpp-tutorial/Images/d0.jpg ) the output will be:
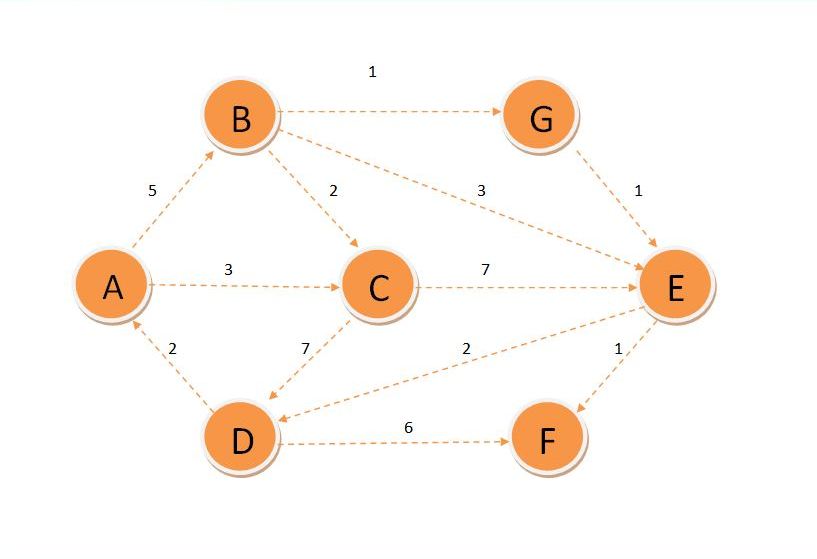{kind=link}
A-B
A-C
A-B-G-E-D
...
Current Output:
|
|
*It shows the correct path but I just can't figure out how to somehow connect them.
So far, I have been able to compute the shortest path costs from the source to each node using Dijkstra's Algorithm. However, I can't seem to figure out how to output the "correct path directions" as seen above.
|
|
Input:
|
|
Last edited on
Alright, so, I was gonna help, but when you started rebuilding your graph I gave up.
I really cannot judge, at this point, how close you are. Your output is not correct at all.
You have mixed up a few very important concepts, at least nominally (by name):
• You call your graph “Node”
• You call your edges “node”
• I am still unsure what you are doing between lines 68 and 82,
besides inexplicably adding nodes to your graph. (I presume you
are trying to prepare for Dijkstra by having a list of all nodes?)
Djikstra works over one structure to create a new, separate structure: the shortest paths to a target node.
All paths start from the root node (which you seem to understand).
After Djikstra’s algorithm finishes, you can then re-create the shortest path by going backwards over the results.
So, here is your given graph, G, listed as (u, Eu), where each E is a list of (v, w):
A: (B 5) (C 3)
D: (A 2) (F 6)
B: (C 2) (G 1) (E 3)
C: (D 7) (E 7)
E: (D 2) (F 1)
G: (E 1)
Next, you should create a separate structure, containing a list of all nodes in the graph, and initialized to infinity (or INT_MAX):
A: ∞
B: ∞
C: ∞
D: ∞
E: ∞
F: ∞
Set your root node to zero. (Your example root node is A.)
A: 0
B: ∞
C: ∞
D: ∞
E: ∞
F: ∞
This is the end of initialization.
Hmm...
I have to think a little harder before I can offer further advice.
(Because I want to tell you to start over.)
I would like to just link to a video, but most videos have some guy talking with a whiteboard and drawing on the graph image itself, which is not helpful. You should see how the second structure is modified as we look at (but do not change) the graph.
[edit] Edge is broken in so many ways...
I really cannot judge, at this point, how close you are. Your output is not correct at all.
You have mixed up a few very important concepts, at least nominally (by name):
• You call your graph “Node”
• You call your edges “node”
• I am still unsure what you are doing between lines 68 and 82,
besides inexplicably adding nodes to your graph. (I presume you
are trying to prepare for Dijkstra by having a list of all nodes?)
Djikstra works over one structure to create a new, separate structure: the shortest paths to a target node.
All paths start from the root node (which you seem to understand).
After Djikstra’s algorithm finishes, you can then re-create the shortest path by going backwards over the results.
So, here is your given graph, G, listed as (u, Eu), where each E is a list of (v, w):
A: (B 5) (C 3)
D: (A 2) (F 6)
B: (C 2) (G 1) (E 3)
C: (D 7) (E 7)
E: (D 2) (F 1)
G: (E 1)
Next, you should create a separate structure, containing a list of all nodes in the graph, and initialized to infinity (or INT_MAX):
A: ∞
B: ∞
C: ∞
D: ∞
E: ∞
F: ∞
Set your root node to zero. (Your example root node is A.)
A: 0
B: ∞
C: ∞
D: ∞
E: ∞
F: ∞
This is the end of initialization.
Hmm...
I have to think a little harder before I can offer further advice.
(Because I want to tell you to start over.)
I would like to just link to a video, but most videos have some guy talking with a whiteboard and drawing on the graph image itself, which is not helpful. You should see how the second structure is modified as we look at (but do not change) the graph.
[edit] Edge is broken in so many ways...
Last edited on
Just to flesh out a bit of what @duthomas mentioned...
This is a poorly designed struct. It contains
+ 1) A source node
+ 2) A vector of destination nodes, one for each edge leaving the source node
+ 3) A vector of costs, one for each edge leaving the source node
First of all, it is called node, yet contains 1 source node and multiple destination nodes. This is poor naming conventions.
Also, we have 2 things inside this struct that correlate to specific edges. That should be a hint that these 2 fields should be much more closely associated. So, maybe they should be wrapped inside a new struct (or class):
The overall class is not really a node. The node is a location in the graph, represented (in this case) by a string. Your source and dest fields are nodes. Your overall structure is really possible legs to travel. So, the same content could be represented as:
It's been too long since I coded Dijkstra's algorithm, and I don't have time to delve into my algorithm books, so I can't help you with the functionality. But getting the data laid out properly and naming things consistently is the foundation of a good design.
|
|
This is a poorly designed struct. It contains
+ 1) A source node
+ 2) A vector of destination nodes, one for each edge leaving the source node
+ 3) A vector of costs, one for each edge leaving the source node
First of all, it is called node, yet contains 1 source node and multiple destination nodes. This is poor naming conventions.
Also, we have 2 things inside this struct that correlate to specific edges. That should be a hint that these 2 fields should be much more closely associated. So, maybe they should be wrapped inside a new struct (or class):
|
|
The overall class is not really a node. The node is a location in the graph, represented (in this case) by a string. Your source and dest fields are nodes. Your overall structure is really possible legs to travel. So, the same content could be represented as:
|
|
It's been too long since I coded Dijkstra's algorithm, and I don't have time to delve into my algorithm books, so I can't help you with the functionality. But getting the data laid out properly and naming things consistently is the foundation of a good design.
@doug4
Careful there... you are picking on stuff that isn’t necessarily wrong, and giving an odd name to a vertex yourself.
@hixtus
However, there is a valid point in structural organization. The shape of your graph can help or hinder; currently it is hindering you.
In the simplest form, a directed graph can be just a 2D integer array. Here is the graph you have linked in the d0.jpg as an array:
So, for example, there is an edge from row A to column B with weight 5, meaning A→B = 5.
However, row B to column A has an invalid edge weight, meaning B↛A (B does not go to A).
If I were to implement this in code, I might be tempted to write something like:
Where edge A→B is
But, that’s not only old-school, it can be done better.
Goals:
• Keep the easy G(u,v) lookup for an edge weight.
• Eliminate “special” values (like -1) by eliminating non-edges.
• Keep easy check for u→v exists
• Keep easy iteration over the graph
First, indexing.
In your code, you use a std::string for the vertex names. That’s fine. I often do that myself, even though node names in homework assignments like this are typically a single char. The 2D array thing kind of makes that uncomfortable, but not especially difficult, but who cares? 2D arrays are so last year.
Since we have decided on a specific type for our vertex names (a std::string), let’s formalize that:
And while we are at it, our weight should be typed as well:
Now to think a second. Each edge in a graph is an association: Vertex u associates with Vertex v having weight w.
In our 2D array, that was easy: row u to column v has value w.
That simple association makes it tempting to write a struct like:
A graph then could be a list of those:
But now we have a problem. With our 2D array, I could easily access any u→u edge by simply saying
Except now I need to search my graph (vector) just to find the right combination of u and v!
Thinking hard, I realize that each node may have multiple edges leading from it, and update my struct to this:
Great! Now I only have to search my graph to find u.
Oh, but then I still have to search
Bummer.
Let’s step back, and see if there is a better way.
Remember, we are messing with an association. In an array, we associate an integer index (0, 1, 2, ...) with the value in the array. In our graph, we do that twice:
That first element is also an array, so there is again an association, this time between an integer index and an edge weight:
Simply:
The change we wish to make is that we no longer want integer-to-array then integer-to-weight associations. We want a Vertex-to-Edge and Edge-to-Weight assocation.
That is:
G["A"] --> an Edge
G["A"]["B"] --> a Weight
In C++, an arbitrary associative array is called a “map”, and you get one by #including <map>. Once you do, you can make the ‘edge’ association for a whole collection of edges:
This easily takes the place of the entire BadEdges struct and gives us a very convenient lookup pattern. Given a vertex's Edges, we can find any edge by naming the target vertex v:
And just as the 2D array G[0] is a collection of edges leading from vertex u, we can create a map to do the same:
Lookup syntax is now our friend:
Beyond that, we can also loop through the edges with ease:
It is also easily possible to test whether an association exists:
To recap, we now have the following structure:
Did we accomplish our goals?
• Keep the easy G(u,v) lookup for an edge weight.
Yes.
• Eliminate “special” values (like -1) by eliminating non-edges.
Yes.
If u→v does not exist, there is no u→v association (no memory used) in the graph
• Keep easy check for u→v exists
Yes.
• Keep easy iteration over the graph
Yes.
Any caveats?
Yes.
Care must be taken to check that everything exists before using
So, what about friggin’ Dijkstra’s Algorithm?!!!
That’s easy. I’ll get back to that next time I post... Gonna eat lunch now.
The point of this entire post is that data structure matters.
Of course, you most certainly canperform Dijkstra’s on your existing structure.
That isn’t the issue, though.
The problem was that your current structure was making it significantly more difficult to reason about your algorithm. It led to:
• naming problems
• additional code (and duplication of code) (to get around structural deficiencies)
• additional objects
All of these are symptoms of struggling to clearly understand the code objectives.
When I get back I’ll take some time to work through Dijkstra’s algorithm in a shockingly simple and clear way. :O)
Because Dijkstra’s algorithm is, actually, brilliantly simple!
(I have been half-heartedly looking for an online video that explains it the way I want, but haven’t found one.)
(And, thinking back, I have surprised myself at how many times I have written an academic implementation of Dijkstra’s algorithm...)
Careful there... you are picking on stuff that isn’t necessarily wrong, and giving an odd name to a vertex yourself.
@hixtus
However, there is a valid point in structural organization. The shape of your graph can help or hinder; currently it is hindering you.
In the simplest form, a directed graph can be just a 2D integer array. Here is the graph you have linked in the d0.jpg as an array:
A B C D E F G A - 5 3 - - - - B - - 2 - 3 - 1 C - - - 7 7 - - D 2 - - - - 6 - E - - - 2 - 1 - F - - - - - - - G - - - - 1 - - |
So, for example, there is an edge from row A to column B with weight 5, meaning A→B = 5.
However, row B to column A has an invalid edge weight, meaning B↛A (B does not go to A).
If I were to implement this in code, I might be tempted to write something like:
|
|
Where edge A→B is
G[0][1] (A==0, B==1).But, that’s not only old-school, it can be done better.
Goals:
• Keep the easy G(u,v) lookup for an edge weight.
• Eliminate “special” values (like -1) by eliminating non-edges.
• Keep easy check for u→v exists
• Keep easy iteration over the graph
First, indexing.
In your code, you use a std::string for the vertex names. That’s fine. I often do that myself, even though node names in homework assignments like this are typically a single char. The 2D array thing kind of makes that uncomfortable, but not especially difficult, but who cares? 2D arrays are so last year.
Since we have decided on a specific type for our vertex names (a std::string), let’s formalize that:
|
|
And while we are at it, our weight should be typed as well:
|
|
Now to think a second. Each edge in a graph is an association: Vertex u associates with Vertex v having weight w.
In our 2D array, that was easy: row u to column v has value w.
That simple association makes it tempting to write a struct like:
|
|
Don’t do this, though. Just say "NO!" |
A graph then could be a list of those:
|
|
But now we have a problem. With our 2D array, I could easily access any u→u edge by simply saying
G[u][v]. Except now I need to search my graph (vector) just to find the right combination of u and v!
Thinking hard, I realize that each node may have multiple edges leading from it, and update my struct to this:
|
|
Hey man, I said "no". |
Great! Now I only have to search my graph to find u.
Oh, but then I still have to search
G[index_of_u].vs to find v.Bummer.
Let’s step back, and see if there is a better way.
Remember, we are messing with an association. In an array, we associate an integer index (0, 1, 2, ...) with the value in the array. In our graph, we do that twice:
G[0] gives us access to the first element element of the array: { _, 5, 3, _, _, _, _ },.That first element is also an array, so there is again an association, this time between an integer index and an edge weight:
{ _, 5, 3, _, _, _, _ }[1] gives us the weight 5.Simply:
G[0][1] == 5. Right?The change we wish to make is that we no longer want integer-to-array then integer-to-weight associations. We want a Vertex-to-Edge and Edge-to-Weight assocation.
That is:
G["A"] --> an Edge
G["A"]["B"] --> a Weight
In C++, an arbitrary associative array is called a “map”, and you get one by #including <map>. Once you do, you can make the ‘edge’ association for a whole collection of edges:
|
|
This easily takes the place of the entire BadEdges struct and gives us a very convenient lookup pattern. Given a vertex's Edges, we can find any edge by naming the target vertex v:
|
|
And just as the 2D array G[0] is a collection of edges leading from vertex u, we can create a map to do the same:
|
|
Lookup syntax is now our friend:
|
|
Beyond that, we can also loop through the edges with ease:
|
|
It is also easily possible to test whether an association exists:
|
|
To recap, we now have the following structure:
|
|
Did we accomplish our goals?
• Keep the easy G(u,v) lookup for an edge weight.
Yes.
G[u][v] == w • Eliminate “special” values (like -1) by eliminating non-edges.
Yes.
If u→v does not exist, there is no u→v association (no memory used) in the graph
• Keep easy check for u→v exists
Yes.
if (G.contains(u) and G[u].contains(v)) ... • Keep easy iteration over the graph
Yes.
for (auto [u, e] : G) to iterate over vertices with any outgoing edges efor (auto [v, w] : e) for edges u→v with weight wAny caveats?
Yes.
G[u][v] will create nodes and edges if any of u, v, or u→v do not exist.Care must be taken to check that everything exists before using
G[u][v].So, what about friggin’ Dijkstra’s Algorithm?!!!
That’s easy. I’ll get back to that next time I post... Gonna eat lunch now.
The point of this entire post is that data structure matters.
Of course, you most certainly canperform Dijkstra’s on your existing structure.
That isn’t the issue, though.
The problem was that your current structure was making it significantly more difficult to reason about your algorithm. It led to:
• naming problems
• additional code (and duplication of code) (to get around structural deficiencies)
• additional objects
All of these are symptoms of struggling to clearly understand the code objectives.
When I get back I’ll take some time to work through Dijkstra’s algorithm in a shockingly simple and clear way. :O)
Because Dijkstra’s algorithm is, actually, brilliantly simple!
(I have been half-heartedly looking for an online video that explains it the way I want, but haven’t found one.)
(And, thinking back, I have surprised myself at how many times I have written an academic implementation of Dijkstra’s algorithm...)
Ok, so, time to condiser Dijkstra’s Algorithm.
Dijkstra’s algorithm has a single purpose:
• Find the shortest path from a specific source vertex s to every other vertex v.
What makes Dijkstra’s special over, say, Floyd-Warshall’s is that Dijkstra’s produces results that let you reverse-engineer the actual paths. In other words, you can create a new graph (a subset of the original graph) using the results.
There are variations
Not only does the way that it is computed vary, but the output goals itself may vary. The most common variations can be expressed by the following table:
to all v to one v
┌──────────┬──────────┐
find a path │ standard │ │
│ Dijkstra │ │
├──────────┼──────────┤
find all paths │ │ │
│ │ │
└──────────┴──────────┘
The “standard” Dijkstra’s algorithm is what we will be working on here. The other variations add a little complexity to the code that you do not need to worry about yet.
The Graph
For purposes of our discussion, we need a directed graph to explore, preferably something really simple:
A → B = 3
A → C = 7
B → C = 2
Pictorally, it could be expressed as
Using your input format, this graph can be expressed as:
And, as a 2D array:
You may notice that it is both acyclic and that only one shortest path a ↝ c exists. This is not required, but it does reduce the size of the discussion that follows. You could easily add an edge a → c = 5 and have two shortest paths a ↝ c; the following will still work without change.
Structures
As discussed above, we have our Graph structure:
DA takes as argument two things: a
DA produces a collection of:
• vertices V′ that can be reached from s
• minimum weight for each s ↝ v for all v ∊ V′
Can we express this collection using any of our extant structures?
We sure can!
Be careful here. The result is a new graph, but the new graph is not a subset of the original graph!
That is, it is a collection of new edges leading from a.
If we were to compute DA for our example graph, the result should be a ↝ c with minimum weight 5. That makes a new graph of:
(A) → 5 → (C)
But our original graph’s a → c is 7. The path a ↝ c = 5 in the original graph is a → b → c.
Not to worry! We can use the new collection of edges to find the list of original edges in the original graph — that’s the point, actually. It just isn’t part of Dijkstra’s Algorithm. DA only produces this new collection of edges. That being the case, we should probably name this collection something different, even if it has exactly the same structure as our graph’s
You are right! We don’t actually need these extra names. Do it anyway. Being explicit and clear about what we are messing with is important to understanding what the code does.
At this point, we can declare our DA function prototype:
Heh, gonna take a break. Then we’ll get into DA’s inner workings.
Dijkstra’s algorithm has a single purpose:
• Find the shortest path from a specific source vertex s to every other vertex v.
What makes Dijkstra’s special over, say, Floyd-Warshall’s is that Dijkstra’s produces results that let you reverse-engineer the actual paths. In other words, you can create a new graph (a subset of the original graph) using the results.
There are variations
Not only does the way that it is computed vary, but the output goals itself may vary. The most common variations can be expressed by the following table:
to all v to one v
┌──────────┬──────────┐
find a path │ standard │ │
│ Dijkstra │ │
├──────────┼──────────┤
find all paths │ │ │
│ │ │
└──────────┴──────────┘
The “standard” Dijkstra’s algorithm is what we will be working on here. The other variations add a little complexity to the code that you do not need to worry about yet.
The Graph
For purposes of our discussion, we need a directed graph to explore, preferably something really simple:
A → B = 3
A → C = 7
B → C = 2
Pictorally, it could be expressed as
3 → (B) ↑ ↓ (A) 2 ↓ ↓ 7 → (C) |
Using your input format, this graph can be expressed as:
|
|
And, as a 2D array:
|
|
You may notice that it is both acyclic and that only one shortest path a ↝ c exists. This is not required, but it does reduce the size of the discussion that follows. You could easily add an edge a → c = 5 and have two shortest paths a ↝ c; the following will still work without change.
Structures
As discussed above, we have our Graph structure:
|
|
DA takes as argument two things: a
Graph G and a source Vertex s.DA produces a collection of:
• vertices V′ that can be reached from s
• minimum weight for each s ↝ v for all v ∊ V′
Can we express this collection using any of our extant structures?
We sure can!
Edges!Be careful here. The result is a new graph, but the new graph is not a subset of the original graph!
That is, it is a collection of new edges leading from a.
If we were to compute DA for our example graph, the result should be a ↝ c with minimum weight 5. That makes a new graph of:
(A) → 5 → (C)
But our original graph’s a → c is 7. The path a ↝ c = 5 in the original graph is a → b → c.
Not to worry! We can use the new collection of edges to find the list of original edges in the original graph — that’s the point, actually. It just isn’t part of Dijkstra’s Algorithm. DA only produces this new collection of edges. That being the case, we should probably name this collection something different, even if it has exactly the same structure as our graph’s
Edges. |
|
You are right! We don’t actually need these extra names. Do it anyway. Being explicit and clear about what we are messing with is important to understanding what the code does.
At this point, we can declare our DA function prototype:
|
|
Heh, gonna take a break. Then we’ll get into DA’s inner workings.
You know, I was going to introduce the previous vertex mapping after the basic algorithm, but now I am thinking that was a mistake...
I may revise the last post some...
I may revise the last post some...
So... I’m doing a really terrible job of explaining this stuff.
Also, I am circling around the way the algorithm was explained to me, by a human standing in front of a whiteboard. I cannot do that here, and trying to reconcile data structures and the algorithm at the same time.
Simply put, I didn’t give it sufficient thought.
I am unhappy about the videos online, though perhaps this one does it best.
https://www.youtube.com/watch?v=pVfj6mxhdMw
It has issues, though. Besides the author’s British accent (which may be an issue for some), the imagery does not always sync well with the explanation. That, and the author tends to apply changes en mass and in two separate passes, instead of at the point of action during the explanation. To wit:
When an improved minimum weight/distance is found, the table should be immediately updated with the new minimum weight and the previous vertex for the vertex under examination.
If anyone cares about this thread still, post and I’ll respond with a simple DA that you can’t possibly submit for grading without instant suspicion of having cheated. Be warned, my algorithm looks very much like what you can find on Wikipedia, even as C++ code.
Also, I am circling around the way the algorithm was explained to me, by a human standing in front of a whiteboard. I cannot do that here, and trying to reconcile data structures and the algorithm at the same time.
Simply put, I didn’t give it sufficient thought.
I am unhappy about the videos online, though perhaps this one does it best.
https://www.youtube.com/watch?v=pVfj6mxhdMw
It has issues, though. Besides the author’s British accent (which may be an issue for some), the imagery does not always sync well with the explanation. That, and the author tends to apply changes en mass and in two separate passes, instead of at the point of action during the explanation. To wit:
When an improved minimum weight/distance is found, the table should be immediately updated with the new minimum weight and the previous vertex for the vertex under examination.
If anyone cares about this thread still, post and I’ll respond with a simple DA that you can’t possibly submit for grading without instant suspicion of having cheated. Be warned, my algorithm looks very much like what you can find on Wikipedia, even as C++ code.
Topic archived. No new replies allowed.